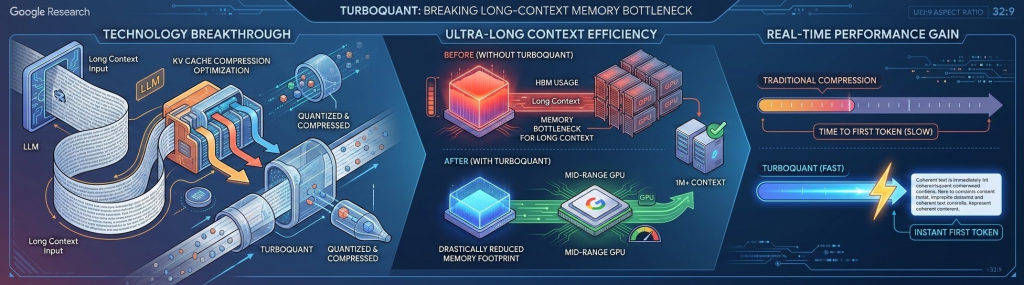
技术突破: Google 发布的 TurboQuant 方案专门针对大模型推理中的“KV 缓存压缩”进行了底层优化。
效能飞跃: 在处理百万级超长上下文(Long-context)时,该技术能显著降低推理显存占用,使中端 GPU 也能运行原本需要万卡集群的任务。
实时性增强: 相比传统的全量压缩,TurboQuant 在保持高保真度的同时,极大提升了模型响应的首字延迟(Time to First Token)。
久湛洞察: 这是长文本处理的“平民化时刻”。对于需要频繁检索大规模历史文档(如复杂技术规范、长周期实验记录)的垂直行业,TurboQuant 意味着可以在更低成本的硬件上部署更高性能的分析智能体,不再受限于昂贵的顶级算力集群显存上限,极大地降低了企业私有化部署的门槛。
关键词: TurboQuant、Google Research、KV 缓存压缩、长文本处理
信息来源: 《Medium (Vishal Mysore)》2026 年 4 月技术专题 https://medium.com/@visrow/the-biggest-ai-trends-and-tools-emerging-in-april-2026-8a491e6d546f